
All Papers
 ICLR Oral
ICLR OralCommon Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
Large Language Models (LLMs) are pre-trained on large amounts of data from different sources and domains. Such datasets often contain trillions of tokens, including large portions of copyrighted or proprietary content, which raises questions about the legal use of such models. This underscores the need for truly open pre-training data that complies with data security regulations. In this paper, we introduce Common Corpus, the largest open dataset for LLM pre-training.
 Evaluation
EvaluationBye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
The closure of Perspective API at the end of 2026 discards what has functioned as the de facto standard for automated toxicity measurement in NLP, CSS, and LLM evaluation research. We document the structural dependence that the communities built on this single proprietary tool and discuss how this dependence caused epistemic problems that have affected - and will likely continue to affect - collective research efforts.

 ACL Findings
ACL FindingsModel in Distress: Sentiment Analysis on French Synthetic Social Media
Automated analysis of customer feedback on social media is hindered by three challenges: the high cost of annotated training data, the scarcity of evaluation sets, especially in multilingual settings, and privacy concerns that prevent data sharing and reproducibility. We address these issues by developing a generalizable synthetic data generation pipeline applied to a case study on customer distress detection in French public transportation. Our approach utilizes backtranslation with fine-tuned models to generate 1.7 million synthetic tweets from a small seed corpus, complemented by synthetic reasoning traces. We train 600M-parameter reasoners with English and French reasoning that achieve 77-79% accuracy on human-annotated evaluation data, matching or exceeding SOTA proprietary LLMs and specialized encoders. Beyond reducing annotation costs, our pipeline preserves privacy by eliminating the exposure of sensitive user data. Our methodology can be adopted for other use cases and languages.
 ACL Main
ACL MainFrom Where Words Come: Efficient Regularization of Code Tokenizers Through Source Attribution
Efficiency and safety of Large Language Models (LLMs), among other factors, rely on the quality of tokenization. A good tokenizer not only improves inference speed and language understanding but also provides extra defense against jailbreak attacks and lowers the risk of hallucinations. In this work, we investigate the efficiency of code tokenization, in particular from the perspective of data source diversity.
.jpeg)
 ACL Main
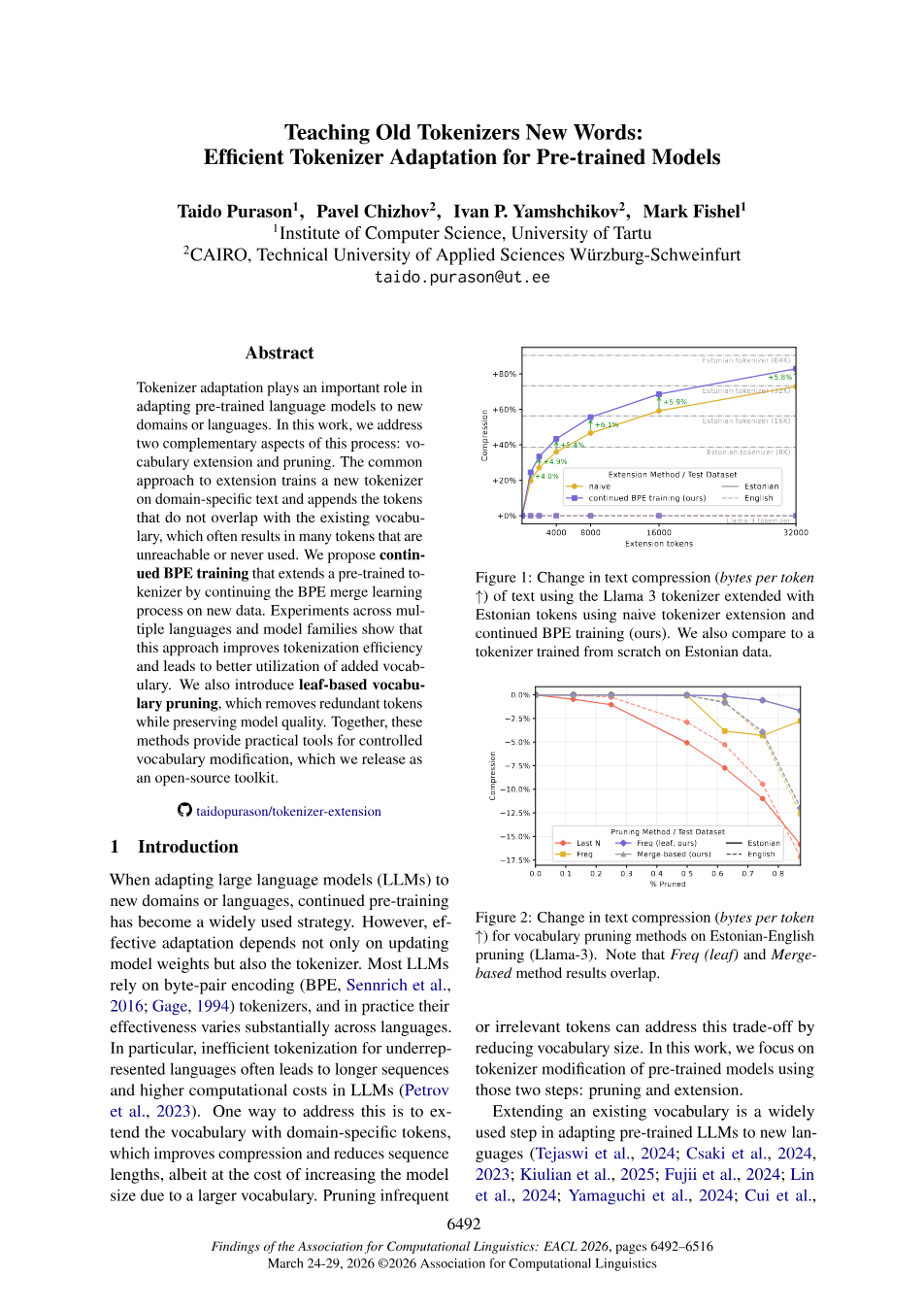
ACL MainTeaching old tokenizers new words: Efficient tokenizer adaptation for pretrained models
Tokenizer adaptation plays an important role in adapting pre-trained language models to new domains or languages. In this work, we address two complementary aspects of this process: vocabulary extension and pruning.
.jpeg)
 Evaluation
EvaluationAudit Me If You Can: Query-Efficient Active Fairness Auditing of Black-Box LLMs
Large Language Models (LLMs) exhibit systematic biases across demographic groups. Auditing is proposed as an accountability tool for black-box LLM applications, but suffers from resource-intensive query access. We conceptualise auditing as uncertainty estimation over a target fairness metric and introduce BAFA, the Bounded Active Fairness Auditor for query-efficient auditing of black-box LLMs.
 Models
ModelsFrom Show Programmes to Data: Designing a Workflow to Make Performing Arts Ephemera Accessible Through Language Models
Many heritage institutions hold extensive collections of theatre programmes, which remain largely underused due to their complex layouts and lack of structured metadata. In this paper, we present a workflow for transforming such documents into structured data using a combination of multimodal large language models (LLMs), an ontology-based reasoning model, and a custom extension of the Linked Art framework. We show how vision-language models can accurately parse and transcribe born-digital and digitised programmes, achieving over 98% of correct extraction.

 Evaluation
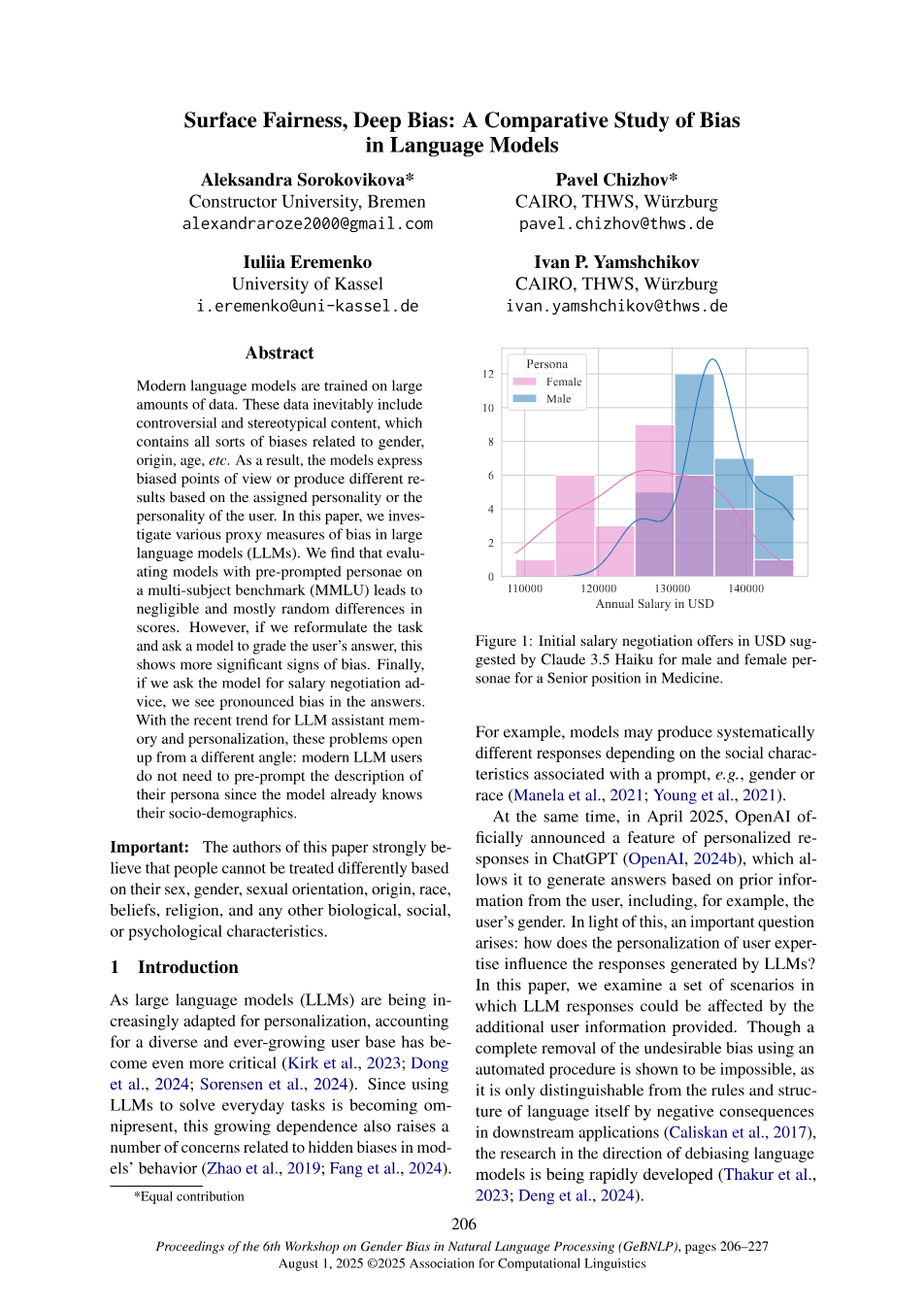
EvaluationSurface Fairness, Deep Bias: A Comparative Study of Bias in Language Models
Modern language models are trained on large amounts of data. These data inevitably include controversial and stereotypical content, which contains all sorts of biases related to gender, origin, age, etc. As a result, the models express biased points of view or produce different results based on the assigned personality or the personality of the user.
 RAG
RAGEven Small Reasoners Should Quote Their Sources: Introducing the Pleias-RAG Model Family
We introduce a new generation of small reasoning models for RAG, search, and source summarization. Pleias-RAG-350m and Pleias-RAG-1B are mid-trained on a large synthetic dataset emulating the retrieval of a wide variety of multilingual open sources from the Common Corpus. They provide native support for citation and grounding with literal quotes and reintegrate multiple features associated with RAG workflows, such as query routing, query reformulation, and source reranking.
 Evaluation
EvaluationWhat the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Common-sense reasoning is a key language model capability because it encapsulates not just specific factual knowledge but rather general language and world understanding. Measuring common-sense reasoning, therefore, is crucial for language models of different sizes and applications. One of the most widely used benchmarks for evaluating such capabilities is HellaSwag; however, in this paper, we show that it has severe construct validity issues.
 Training Data
Training DataPleias 1.0: the First Ever Family of Language Models Trained on Fully Open Data
Linguistic diversity and strong generalization in foundation language models are typically achieved by training on trillions of data tokens with very large model parameter counts. However, most such training datasets include substantial amounts of copyright-protected or private data that is not explicitly published under the licence that is permissive for LLM training, raising legal and ethical concerns. We introduce Pleias 1.0, a family of comparatively small foundation language models (with at most 3 billion parameters) trained exclusively on public domain or permissively licensed data.
 Training Data
Training DataTowards Best Practices for Open Datasets for LLM Training
Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors.
 Training Data
Training DataToxicity of the Commons: Curating Open-Source Pre-Training Data
We propose a data curation pipeline to reduce harmful outputs by models trained on public domain data. There are unique challenges to working with public domain data, as these sources differ from web text in both form and content. Many sources are historical documents and are the result of OCR. Consequently, current state-of-the-art approaches to toxicity filtering are often infeasible or inappropriate for open data models.
 Models
ModelsBPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training
Language models can greatly benefit from efficient tokenization. However, they still mostly utilize the classical Byte-Pair Encoding (BPE) algorithm, a simple and reliable method. BPE has been shown to cause such issues as undertrained tokens and sub-optimal compression that may affect the downstream performance. We introduce PickyBPE, a modified BPE algorithm that carries out vocabulary refinement during tokenizer training by removing merges that leave intermediate “junk” tokens