

Sillon: A Specialised 600M Model for Parisian Subway Operator (RATP)
.png)
Pleias trained a 600-million-parameter specialized model for RATP to detect and interpret safety signals in Parisian Subway users’ messages - combining a fully synthetic training pipeline and designed for on-premise deployment. After only three months of development, the model, beating closed models 200x times its size, is now in production at RATP’s sovereign infrastructure on Scaleway.
The Operational Problem
RATP receives massive amounts of user reactions daily: replies, comments, and mentions about their services. Hidden in this volume are critical safety signals: people fainting in the train, medical emergencies, heat waves, security incidents requiring immediate attention. But distinguishing real distress from exaggerated online language is difficult. When someone tweets, for example, "je vais mourir" (I'm going to die), it could mean genuine risk or exacerbated frustration about a delayed train.
A potential solution could rely on a large closed model accessed through API calls with large context engineering. Functionally, it works but to a certain point. Reasoning over complex situations is not reliable and is not discriminatively based on RATP’s internal analytical specialised frameworks, costs scale with volume, reasoning occurs in a black box, and on-premise GDPR-compliant deployment is not possible.
The Importance Of Synthetic Data
This is the kind of problem where classical machine learning hits a wall before it starts. Operational distress is rare in organic data, so the signal is starved. A decade of historical messages (RATP has collected roughly 30 million since 2012) carries heavy drift in language and platform dynamics. And the data itself cannot be shared for annotation or training at scale without creating compliance exposure.
Synthetic data resolves the cold-start problem without compromising user privacy. Instead of training on real tweets, we generate realistic ones grounded in distribution patterns and expose no real users in the process. This allows us to selectively amplify rare distress signals events, as we can regenerate synthetic examples indefinitely. This is the entire point of the pipeline.
What We Built
Pleias trained a 600M parameter model on 1.7 million synthetic messages in combination with SYNTH, our well-known synthetic pretraining corpus with high quality generalist reasoning traces. The synthetic dataset upsamples rare distress cases and introduces plausible scenarios that never appeared in historical data but that the monitoring infrastructure needs to anticipate.
The model is evaluated on a held-out set designed by RATP including 2,000 real messages, each labeled by 9 to 11 human reviewers (407 annotators total), with ground truth resolved through majority voting. It outputs decision labels and, critically, a complete reasoning trace in French in full conformity with RATP’s internal analytical psychometric framework that identifies the triggering phrases, weighs urgency markers, and rules out hypothetical or sarcastic readings.
"Within the RATP, innovation is dedicated to transforming technological advances—on our own or in partnership—into concrete solutions for our operations. Our goal is to be at the right level of technology, where it delivers real value for passengers, staff, and cities. With SILLON, we are demonstrating this expertise alongside partners, in service of technology that is useful, well-managed, and fully integrated with the demands of a major public transport operator," says Gilles Tauzin, Director of Innovation for the RATP Group.
Results
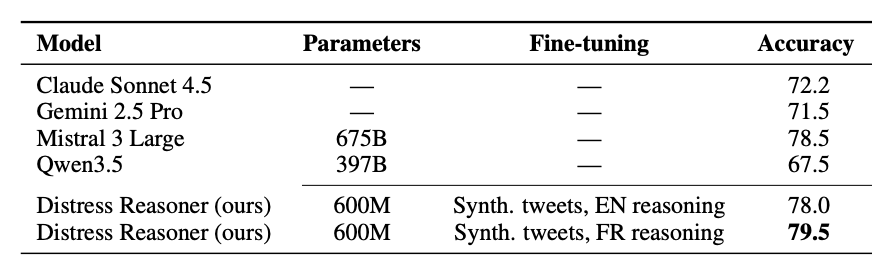
On the human-annotated evaluation set, the model reaches roughly 80% agreement with human reviewers - meaningful in context, since human reviewers themselves disagree on distress labels about 20% of the time. On-premise deployment surpasses the accuracy of previously used very large closed models benchmarked in parallel, while eliminating ongoing API costs and keeping every message inside RATP's infrastructure at inference.
Data Is The New Frontier
This case study extends a thesis we laid out in SYNTH: the new data frontier to the specific constraints of regulated environments: purpose-built synthetic pipelines are the right foundation for specialized AI in industrial contexts.
Synthetic simulations allow work on de-sensitized data and mitigate by design multiple privacy issues that the previous era of machine learning and AI largely ignored and that can no longer be set aside. The compliance problem dissolves by design rather than by patching it afterwards.
They also made it possible to model situations where real observations are scarce or non-existent and generalize high-density reasoning traces at scale making raw data learnable and comprehensible, even despite the high variance of French slang.
This data efficiency collapses the cost of entry. A 600M-parameter model trained on a purpose-built synthetic corpus can match frontier-scale LLMs on targeted tasks, which democratizes AI for organizations significantly augmenting the ROI on their AI use cases, and makes possible the ones for which organisation could not legally route their data to a closed provider.
Full scientific report is published as Model in Distress (ACL 2026).