

Pleias and NVIDIA release Nemotron-Personas-Belgium

Today at VivaTech, Pleias, in collaboration with NVIDIA, is releasing Nemotron-Personas-Belgium, a statistically grounded synthetic persona dataset covering the Belgian population at the level of regions, language communities, and communes. It is the second European dataset in the Nemotron Personas series, following Nemotron-Personas-France, announced in March 2026.
Today at VivaTech, Pleias, in collaboration with NVIDIA, is releasing Nemotron-Personas-Belgium, a statistically grounded synthetic persona dataset covering the Belgian population at the level of regions, language communities, and communes. It is the second European dataset in the Nemotron Personas series, following Nemotron-Personas-France, announced in March 2026, and sharing the same schema as the original Nemotron-Personas-USA, launched during VivaTech last year Both European datasets were produced on Jean-Zay, the French national supercomputer operated by GENCI and IDRIS, from public statistics released under open licences.
The synthesized dataset is being used in production pipelines across healthcare, energy, and telecommunications. The substantive arguments behind the release - what makes Belgium a particularly demanding case, why the choice of European public infrastructure matters, and what the personas actually unlock in practice - follow below.
What Belgium asks of a persona dataset
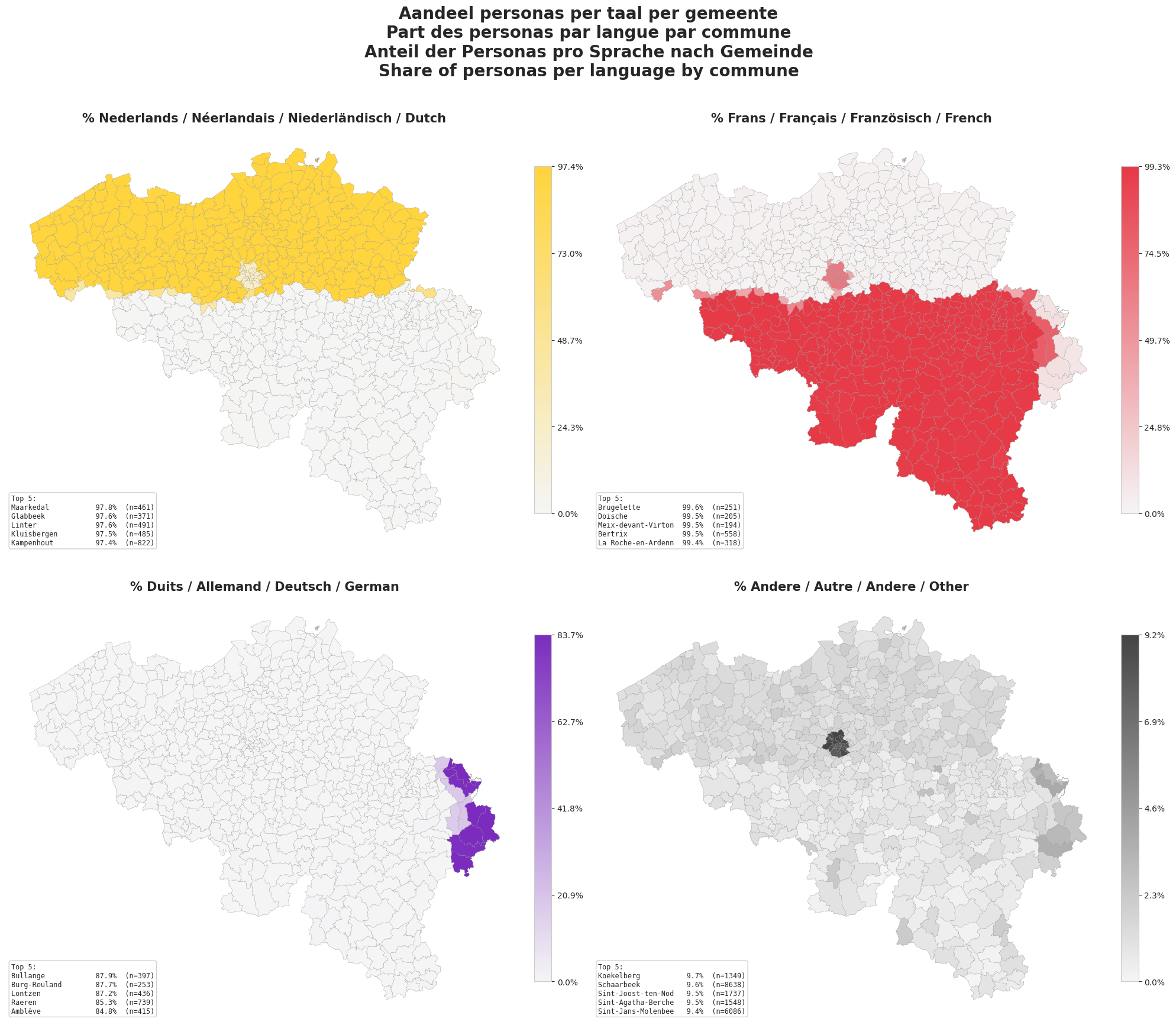
Belgium is a uniquely stratified country that represents many complex European dynamics at a smaller scale. A country of roughly 11.7 million people, three official languages, three federated regions, three language communities, and an administrative landscape where statistics are produced both by Statbel and by regional authorities. And, symbolically, Brussels is a European capital attracting many people throughout the continent.
Names are not distributed uniformly across the territory; surnames carry the trace of internal mobility, of a century of immigration, of the linguistic frontier. Occupational structure differs sharply between Flanders, Wallonia and Brussels-Capital. Household composition and income distributions cut differently across each.
A naive modeling of Belgium as an aggregation of a French-adjacent part and a Dutch-adjacent part would result in a persona space that does not exist in reality, and a synthetic dataset that systematically misrepresents the people the model will eventually encounter, in the same way as the EU is not just the aggregation of 28 countries.
For Belgium, we worked from a single authoritative source: the 2021 federal census from StatBel. It covers what we need at commune granularity, from demographics, education, marital status, and household structure to surnames, first names by linguistic region, and wage curves. One vintage, one provider, no cross-referencing to patch gaps.
The one piece of structure we added on top is a heritage signal, derived from Belgian surname distributions. It drives first-name selection and, because the network has joint structure, the home language of each persona. We did not model foreign-born or naturalized status as separate dimensions; heritage is purely a naming and language-routing variable, not a proxy for nationality.
Language is where Belgium gets distinctive. The country has three official languages: Dutch, French, and German. Home-language use is not tracked in census data, but it is essential for any useful persona of a Belgian. We reconstructed it per commune by combining the official linguistic-region boundaries, including the nine German-speaking communes of the Ostkantons, with heritage-conditioned priors. A persona from Eupen speaks German, one from Antwerp speaks Dutch, one from Liège speaks French, and Brussels personas show the expected bilingual French and Dutch overlap. That language axis is what makes Belgian personas distinct from the French ones we built earlier.
What this unlocks in practice
Most projects across regulated sectors in Europe share the same constraint: real data is sensitive, redacted, or simply unavailable. Synthetic data is quite often the only path; and synthetic data is only as useful as the demographic backbone it rests on.
Healthcare is where the stakes become most visible. One of the recent use cases was built with Nemotron-Personas - Lamina, a spine healthcare AI assistant built with specialized language models trained without patient data leaving controlled environments. Lamina draws on the Nemotron Personas series across France, Belgium and the United States, and the personas play two distinct roles.
The first is evaluation. A clinical assistant has to behave consistently across the actual demographic spectrum of patients it will encounter, not just a notional average user. The personas make it possible to test, region by region and profile by profile, where the model holds up and where it does not.
The second is generation. From an extremely limited seed of real patient information, the personas let us expand a handful of cases into a population of demographically coherent profiles, and from there synthesize clinical conversations, intake notes, and follow-up exchanges that reflect the diversity a spine clinic actually sees. The word that matters here is efficient: with the demographic distribution built in, we do not need to oversample to reach coverage.
Better grounded data is what makes a small efficient regional-specific model viable in the first place.
Nemotron-Personas-Belgium is available now on Hugging Face: here
Nemotron-Personas-France remains available: here